#SEO 山西翼城县免费公司网站建设 山西翼城县免费公司网站建设在网上,关于"山西翼城县免费公司网站建设"的讨论十分热门。本文将为您提供关于这个话题的详细信息,希望可以解决您的疑惑。翼城县地理位置翼城县位于山西省中部,地理位置优越。在物流方面,有许多运输公司和配货中心便利地位于翼城县境内,如临汾市、洪洞县等。这些地方为翼城县的企业提供了便捷的物流支持。免费公司网站建设服务对于翼城县的企业而言,建设一个免费的公司网站是非常重... 2024-04-26 23:29:58 网站建设 3
#SEO 江西永修县免费百度优化攻略 江西永修县免费百度优化攻略一、优化网页关键词在进行百度优化时,要首先确定网页的关键词。根据江西永修县的特点和目标受众,选择适合的关键词进行优化。关键词的选择要具有一定的量和质,同时要考虑竞争对手的情况,选择能够带来流量和转化的关键词进行优化。二、优化网页内容优化网页内容是百度优化的关键之一。在编写网页内容时,要注意内容的原创性和质量。内容要符合用户的需求,同时要包含关键词,并合理布局。... 2024-04-26 23:29:28 网站建设 3
#SEO 广东连州市免费SEO优化攻略 广东连州市免费SEO优化攻略在当今数字化发展迅猛的时代,SEO优化已成为企业提升品牌曝光度和网站流量的重要手段之一。而在广东省的连州市,免费SEO优化更是备受企业关注和追捧。本文将为您提供一份全面的广东连州市免费SEO优化攻略,帮助您将网站推广得更加高效和精准。1. 确定目标关键词在进行免费SEO优化之前,首先要确定目标关键词。通过搜索引擎关键词工具或竞争对手分析,找到与您产品或服务相... 2024-04-26 23:28:43 网站建设 3
#云南服务器 云南华宁县建站服务器多少钱 云南华宁县建站服务器多少钱在云南华宁县建站服务器需要考虑的费用包括域名、服务器和网站设计制作等多个方面。对于企业建站而言,不同类型的网站所需费用也有所不同。域名费用域名是网站的地址,在选择域名时需要支付注册费用,通常在55-130元不等。常见的域名后缀有.com、.cn、.cc等,选择合适的域名后需按年缴纳费用。服务器费用服务器类似于U盘,用于存储网站文件、文字、视频、数据库等内容。服... 2024-04-26 23:28:17 服务器 3
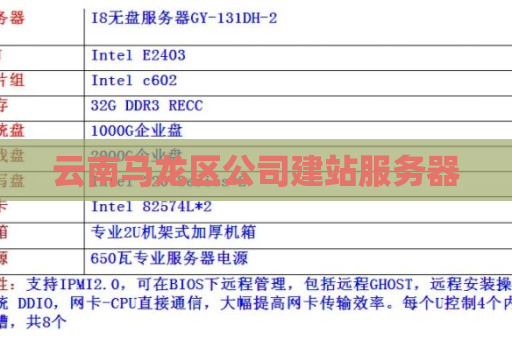
#云南服务器 云南马龙区公司建站服务器 云南马龙区公司建站服务器在当今数字化时代,每个公司都需要一个稳定可靠的服务器来支持他们的业务运营。而云南马龙区公司建站服务器正是为满足这一需求而设计的。本文将介绍该服务器的特点、优势以及如何选择和配置适合公司需求的服务器。服务器特点高性能:云南马龙区公司建站服务器采用最新的硬件设备和处理器,能够处理大量的数据和流量,保证公司网站的流畅运行。可靠稳定:该服务器提供了多重备份和容错机制,保... 2024-04-26 23:28:06 服务器 3
#云南服务器 云南施甸县公司建站服务器 云南施甸县公司建站服务器在网络上,关于"云南施甸县公司建站服务器"的话题一直备受热议。为了帮助大家更好地了解这一主题,我们整理了一些相关信息,希望可以解答您的疑惑。企业建站该怎么选择服务器?在进行企业建站过程中,选择合适的服务器非常重要。服务器是用来存储网站文件的设备,类似于U盘的功能。不同的服务器商收费不同,主要取决于服务器的配置、带宽和容量等因素。一般而言,小型网站的服务器费用在1... 2024-04-26 23:26:21 服务器 3
#SEO 浙江泰顺县免费网站推广 浙江泰顺县免费网站推广欢迎来到浙江泰顺县免费网站推广攻略!如果你是一个有志于推广自己网站的网站管理员,或者只是对网站推广感兴趣,那么你来对地方了!在这篇攻略中,我们将与你分享一些有效的免费网站推广方法,帮助你扩大网站的知名度并吸引更多的访客。无论你是刚起步的新手还是已经有一定经验的老手,希望这些方法能对你有所帮助,并为你的网站带来持续的增长。开始前的准备工作在开始推广网站之前,有一些准... 2024-04-26 23:24:47 网站建设 3
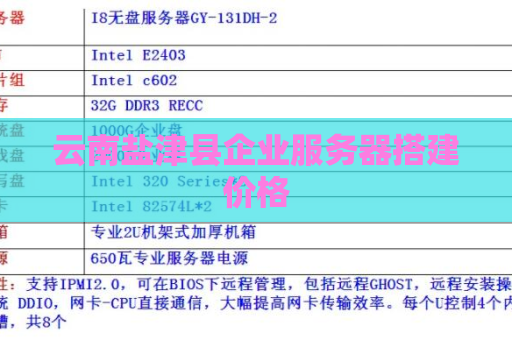
#云南服务器 云南盐津县企业服务器搭建价格 云南盐津县企业服务器搭建价格在今天的数字化时代,企业服务器的搭建已经成为了企业提高运作效率和信息安全的重要举措。而在云南盐津县,作为一个充满活力的地区,企业服务器搭建的需求也越来越大。但是很多企业主对于企业服务器搭建的价格一直存在疑惑,今天我们就来详细了解一下云南盐津县企业服务器搭建的价格情况。1. 服务器硬件价格在选择企业服务器时,首先需要考虑的就是服务器硬件的价格。服务器硬件的价格... 2024-04-26 23:24:38 服务器 3
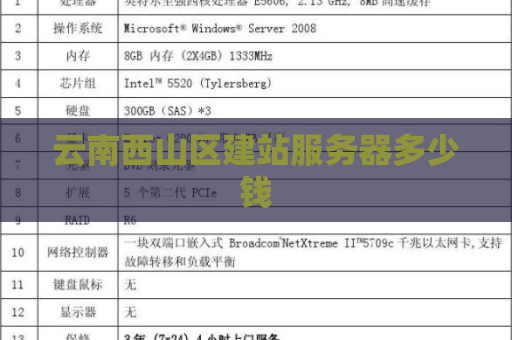
#云南服务器 云南西山区建站服务器多少钱 云南西山区建站服务器多少钱在云南西山区建站服务器需要多少钱呢?这是一个很热门的话题。为了解决大家的疑惑,我们整理了一些相关信息,希望可以帮助到你。首先,针对免费建站网站一级大陆的需求,登烈建站是一个提供高端网站建设和一站式互联网品牌营销建站平台。他们提供了多种模板供选择,覆盖各行各业的建站需求,提供3000+套网站模板供免费使用。无论是个人网站还是企业网站,都能在这里找到合适的模板。对... 2024-04-26 23:22:30 服务器 3
#SEO 云南红塔区建设公司网站不要钱 云南红塔区建设公司网站不要钱云南红塔区建设公司为了让更多的客户了解公司的业务和服务,特别推出了一项独特的活动:建设公司网站不要钱!作为一家专业的建设公司,我们致力于为客户提供优质的建筑工程服务,现在更是为您提供免费搭建公司网站的机会。无论您是企业还是个人,只要选择我们,即可享受免费搭建网站的服务,让您的业务更上一层楼!为什么选择我们?专业团队:我们拥有一支高效专业的团队,能够根据客户需... 2024-04-26 23:21:45 网站建设 3